
北京2024年1月18日 /新闻稿网 - Xinwengao.com/ — 近日,源2.0开源大模型与LLaMA-Factory框架完成全面适配,用户通过LLaMA-Factory,即可快捷、高效地对不同参数规模的源2.0基础模型进行全量微调及高效微调,轻松实现专属大模型。

LLM(大语言模型)微调,是指在大模型的基础上,针对特定任务或领域进行调整和优化,以提升模型的性能和表现,有效的微调方案与工具也正是解决基础大模型落地私有领域的一大利器。基于开源大模型的微调,不仅可以提升LLM对于指令的遵循能力,也能通过行业知识的引入,来提升LLM在专业领域的知识和能力。
当前,业界已经基于LLM开发及实践出了众多的微调方法,如指令微调、基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback)、直接偏好优化(DPO,Direct Preference Optimization)等。以高效微调(PEFT,Parameter-Efficient Fine-Tuning)方案为例,可有效解决内存和计算资源的制约,通过LoRA、QLoRA等高效微调技术,在单张GPU上完成千亿参数的微调训练。因此,一个能够实现上述功能的简洁、高效且易用的微调框架正是开展LLM微调工作的最佳抓手。
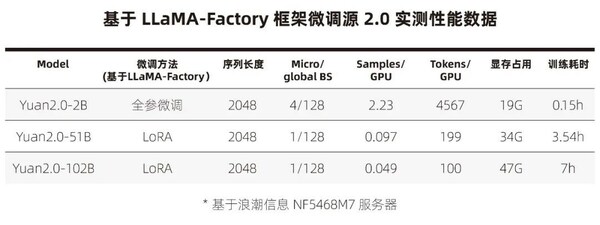
LLaMA-Factory是零隙智能(SeamLessAI)开源的低代码大模型训练框架,旨在为开发者提供可视化训练、推理平台及一键配置模型训练。基于LLaMA-Factory, 用户可轻松选择业界最全面的微调方法和优化技术,通过使用私域数据,或是LLaMA-Factory内置的中文数据集(GPT-4优化后的alpaca中文数据集、ShareGPT数据集和llama-factory提供的模型认知数据集),对源2.0进行轻松微调,基于有限算力完成领域大模型的定制开发。实测数据显示,在一台搭载8颗GPU的主流AI服务器NF5468M7,7小时内即可实现千亿模型(Yuan2.0- 102B)的高效指令微调,10分钟即可完成Yuan2.0-2B参数的指令微调,轻松实现即调即用。
Step by Step
单机即可实现千亿参数模型微调
- Step 1: 容器化环境部署,数条指令即可轻松完成
- Step 2: 开源可商用Yuan2.0 Huggingface模型获取
- Step 3: 一键"启动"web UI服务
- Step 4: 构建LLM助手-可视化界面配置完成Yuan2.0微调
- Step 5: 搭建我们的私有LLM助手
GitHub项目地址:
https://github.com/IEIT-Yuan/Yuan-2.0/blob/main/docs/Yuan2_llama-factory.md